7.2. Data mining: fouille de données et intelligence artificielle¶
A partir de données observées et de quelques règles simples notre but est d’apprendre à faire prendre des décisions sur de nouvelles observations. Par exemple, apprendre à reconnaître des visages, ou la langue dans laquelle est écrite un document.
Cette discipline s’appelle le data mining ou machine learning. Elle est en très forte expansion, menée par des compagnies comme Google.
7.2.1. Un peu de botanique: nommer des iris¶
| L’iris Setosa | L’iris Versicolor | L’iris Virginia |
|---|---|---|
 |
 |
 |
Dans les années 30, Edgar Anderson a mesuré 4 attributs de fleurs Iris:
|
|
Pouvons-nous reconnaître les 3 espèces d’Iris, Setosa, Versicolor et Virginia, à partir de ces attributs?
7.2.1.1. Explorer les données¶
Les données “iris” viennent avec scikit-learn:
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
7.2.1.1.1. Les observations des iris¶
Les données décrivant les iris sont accessibles dans le champ “data”:
>>> data = iris.data
C’est un tableau numpy de dimension (150, 4): 150 iris observés et 4 attributs mesurés par iris:
>>> data.shape
(150, 4)
Le nom des attributs (“feature” en anglais) se trouve par:
>>> iris.feature_names
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
Donc data est un tableau 2 entrées, associant chaque iris à ses attibuts listés si dessus.
7.2.1.1.2. Les “classes” d’iris¶
Le nom de l’espèce d’iris correspondant à l’observation est dans le champ “target”, car c’est la cible de notre problème de prédiction:
>>> target = iris.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
C’est un tableau de longueur 150 contenant des entiers: chaque classe est codée par un chiffre, les noms correspondant se trouvent dans:
>>> iris.target_names
array(['setosa', 'versicolor', 'virginica'],
dtype='|S10')
En général, on parle de “classes” d’objects dans un tel problème de reconnaissance d’objects.
7.2.1.1.3. Un peu de visualisation¶
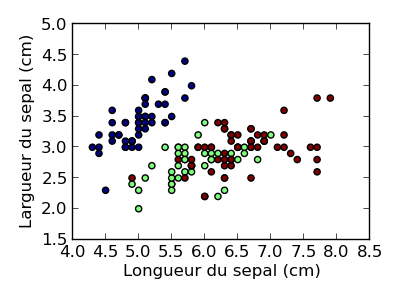
Affichons les types d’iris en fonction des dimensions du sepale (pour cela nous utilisons la commande matplotlib.pyplot.scatter()):
plt.figure(figsize=(4, 3))
plt.scatter(data[:, 0], data[:, 1], c=target)
plt.xlabel('Longueur du sepal (cm)')
plt.ylabel('Largueur du sepal (cm)')



Remarque
Les données sont 150 points dans un espace de dimension 4 (150 observations avec 4 attributs).
Il va nous falloir apprendre une frontière de séparation dans cet espace.
Les variables à prédire sont catégorielles, c’est un problème dit de de classification. Pour une variable à prédire continue (comme l’age du capitaine), on parle de problème de regression.
7.2.1.2. Prédiction au plus proche voisin¶
7.2.1.2.1. L’object classifier¶
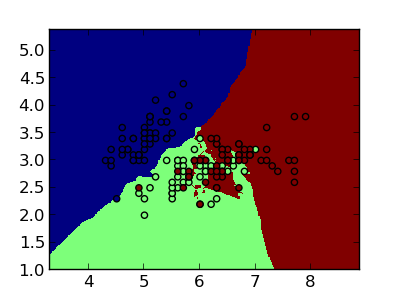
Lorsqu’arrive une observation inconnue, nous allons chercher dans la base de donnée d’entrainement les ‘plus proches voisins’ qui lui ressemblent plus, et nous faisons un vote entre eux pour décider de la classe de l’observation inconnue.
Comme nous avons un problème de classification, il nous faut un “classifier”:
>>> from sklearn import neighbors
>>> clf = neighbors.KNeighborsClassifier()
clf sait apprendre à faire des décisions à partir de données:
>>> clf.fit(data, target)
et prédire sur des données:
>>> clf.predict(data[::10])
array([0, 0, 0, 0, 0, 1, 1, 2, 1, 1, 2, 2, 2, 2, 2])
>>> target[::10]
array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2])
Remarque
Comment faire que un prédire aux plus proches voisins n’ait aucune erreur sur les données d’entraînement?
Pourquoi est-ce illusoir?
7.2.1.2.2. Données de test¶
Pour tester la prédiction sur des données non vues, il nous faut en mettre de coté:
>>> data_train = data[::2]
>>> data_test = data[1::2]
>>> target_train = target[::2]
>>> target_test = target[1::2]
>>> clf.fit(data_train, target_train)
Maintenant, testons la prédiction sur les données de “test”:
>>> np.sum(clf.predict(data_test) - target_test)
1
Une seule erreur!
7.2.2. Classification de documents textes¶
Voir aussi
Pour aller plus loin, la documentation officielle contient beaucoup d’exemples et d’explications : http://scikit-learn.org
